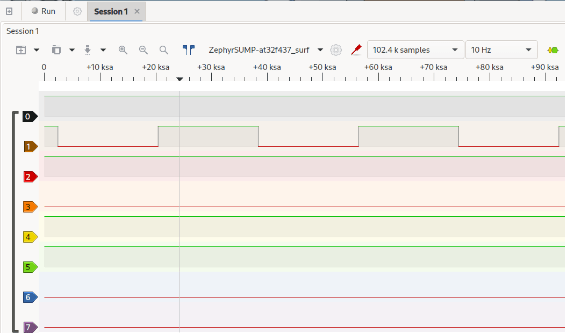
lvgl
作为gl库挺好用的,但是缺少上层ui支持,纯手写有点累人。
squareline说不上好用。
lwip
断言错误:timeout != null
运行后,lwip报错如下
Assertion "sys_timeout: timeout != NULL, pool MEMP_SYS_TIMEOUT is empty" failed at line 3
11 in /workspace/aipi/aithinker_Ai-M6X_SDK/components/net/lwip/lwip/src/core/timeouts.c
解决方法:
在lwipopts_user.h中定义,默认是10,适当增大即可消除这个错误
错误本质是timeout的mem区域定义过小,导致melloc失败
#define MEMP_NUM_SYS_TIMEOUT 20
socket没有必要断开
http是基于socket的一坨文本,传输过程中没有必要一包一个连接,可以一个连接用到底。
正好避免了不断的内存申请和释放。
大数据recv
jellyfin数据包比较大,登录的数据包就超过了3k,超越了MSS大小(1360)。
没想到什么好的解决方法,只能开个大buffer。
讨巧的办法:如果数据到达MSS极限就再收一次,希望不会有恰好的。正常的也许判断下第一包里面的数据size会好些。
cJSON
cJSON的子元素不要delete,全部是用完直接delete根部即可。不然会导致越界错误。
minicom 在lf时换行
参考:https://unix.stackexchange.com/questions/283924/how-can-minicom-permanently-translate-incoming-newline-n-to-crlf
$HOME/.minirc.dfl添加
Jellyfin
登录
大部分指令整理在:
https://github.com/feilongfl/JellyfinBox/issues/5
使用登录数字可以避免在不到4寸的屏上面戳密码
apikey
需要套一层:Mediabrowser Token=”$token”
ref: https://github.com/jellyfin/jellyfin/issues/7190
使用http://jellyfin.lan:8096/api-docs/swagger/index.html可以调试大部分API
转码
对于MCU播放来说,flac之类的无损过于庞大了(也许也能播放),而且音频文件格式也不少,为了通用,通过jellyfin可以自动转码,重点在于transcodingContainer参数
curl 'http://192.168.10.110:8096/Audio/ca6d68582302e6e6fdcb576974db06e9/universal?UserId=c45083f066864d658bbeb7fe9a9b443d&DeviceId=TW96aWxsYS81LjAgKFgxMTsgTGludXggeDg2XzY0KSBBcHBsZVdlYktpdC81MzcuMzYgKEtIVE1MLCBsaWtlIEdlY2tvKSBDaHJvbWUvMTE2LjAuMC4wIFNhZmFyaS81MzcuMzZ8MTY5NjA1OTYyNjg2MA11&audioBitRate=96000&audioCodec=mp3&transcodingContainer=mp3&api_key=86d7bbfa776748a1afa742f28b8c4cc9&PlaySessionId=1696157558093&StartTimeTicks=0&EnableRedirection=true&EnableRemoteMedia=false' \
-H 'Accept: */*' \
-H 'Cache-Control: no-cache' \
-H 'Pragma: no-cache' \
-H 'Range: bytes=0-' \
-H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36' | mplayer -
转码2
貌似jellyfin不支持转换pcm格式,需要改改代码
核心处理在:Jellyfin.Api/Helpers/AudioHelper.cs
通过ffmpegCommandLineArguments来控制ffmpeg进行转码。
编译jellyfin需要在ubuntu等有dpkg的平台才可以编译(linux)
自动转码PCM
参考:https://github.com/jellyfin/jellyfin/pull/10321
jellyfin编译
装ubuntu
装nodejs
参考:https://github.com/nodesource/distributions
装dotnet
参考:https://learn.microsoft.com/en-us/dotnet/core/install/linux-scripted-manual#scripted-install
编译jellyfin-web
需要有个客户端来调试
参考:https://github.com/jellyfin/jellyfin-web
编译jellyfin
调试参考:https://github.com/jellyfin/jellyfin#running-from-the-command-line
./build -t native -p linux.amd64
生成的文件竟然在../bin,这个构建系统可能是有问题吧…
重置服务器
错过了初次向导,导致无法设置密码时候可以使用
rm ~/.config/jellyfin/ -rv
AIPI
声音 – i2s
不知道为啥官方不给个声音例程。。。
官方默认的声音是aipi-eyes-s2的,s1需要用8388_pcm
而且翻遍sdk也没找到解码器…
测试硬件方法
参考:https://segmentfault.com/a/1190000016652277
测试声音可以用下面指令生成一段测试音乐,方便测试
ffmpeg -y -i d.mp3 -acodec pcm_s16le -f s16le -ac 2 -ar 16000 16k.pcm
xxd -i 16k.pcm 16kpcm.h
但是需要注意flash大小,并且注意section。也就能存几句歌左右,不过能听个大概。
同时,DMA每次传输有上限(具体没测试),不能一次传完大的音乐。需要利用isr多次传输。
采样率相关
输出音乐如果女变男或者节奏变慢,需要加快i2s采样率。
如果变成nightcore,那么应该减少采样率
杂音
感觉是传输中有多余字符或字符丢失,但是目前没找到什么好办法
-> Jellyfin服务器下载的数据ffmpeg播放没有问题
-> curl下载数据和MCU 的 lwip socket读取数据不一致(串口打印)
-> python试一下发现socket读回来的ffmpeg也有杂音
-> 看起来socket直接读回来的数据和http下载的有区别
-> 比较两个文件,除了HTTP头,还多出两千多个byte,这个应该就是原因了
-rw-r–r– 1 feilong feilong 15257333 10月 2日 14:19 test.bin
-rw-r–r– 1 feilong feilong 15255040 10月 2日 14:23 wget.pcm
-> 除了标头以外,找到了下面4种差异
0x0a,0x31,0x30,0x30,0x30,0x30,0x0d,0x0a,0x0d
0x0d,0x0a,0x30,0x0d,0x0a,0x0d,0x0a
0x0d,0x0a,0x31,0x30,0x30,0x30,0x30,0x0d,0x0a
0x0d,0x0a,0x63,0x36,0x30,0x30,0x0d,0x0a
看起来HTTP会添加长度说明,奇数个byte的时候,打破了16bit对齐的音频数据


")